Digitalisiere deine Zukunft
Erweitere deine Fähigkeiten und fördere deine Karriere

Alumni-Netzwerk
Beschäftigungsquote
Job in 6 Monaten

Wo unsere Studenten Arbeit finden
Finde deinen Traumjob - wir unterstützen dich auf dem Weg dorthin!


Mijail Febres
Wurde vom Scientist zum Software Developer bei Repower
❝Die Constructor Academy hat mich bei der Vorbereitung auf meine Vorstellungsgespräche sehr unterstützt.❞







Einzigartige Unterrichtsmethoden
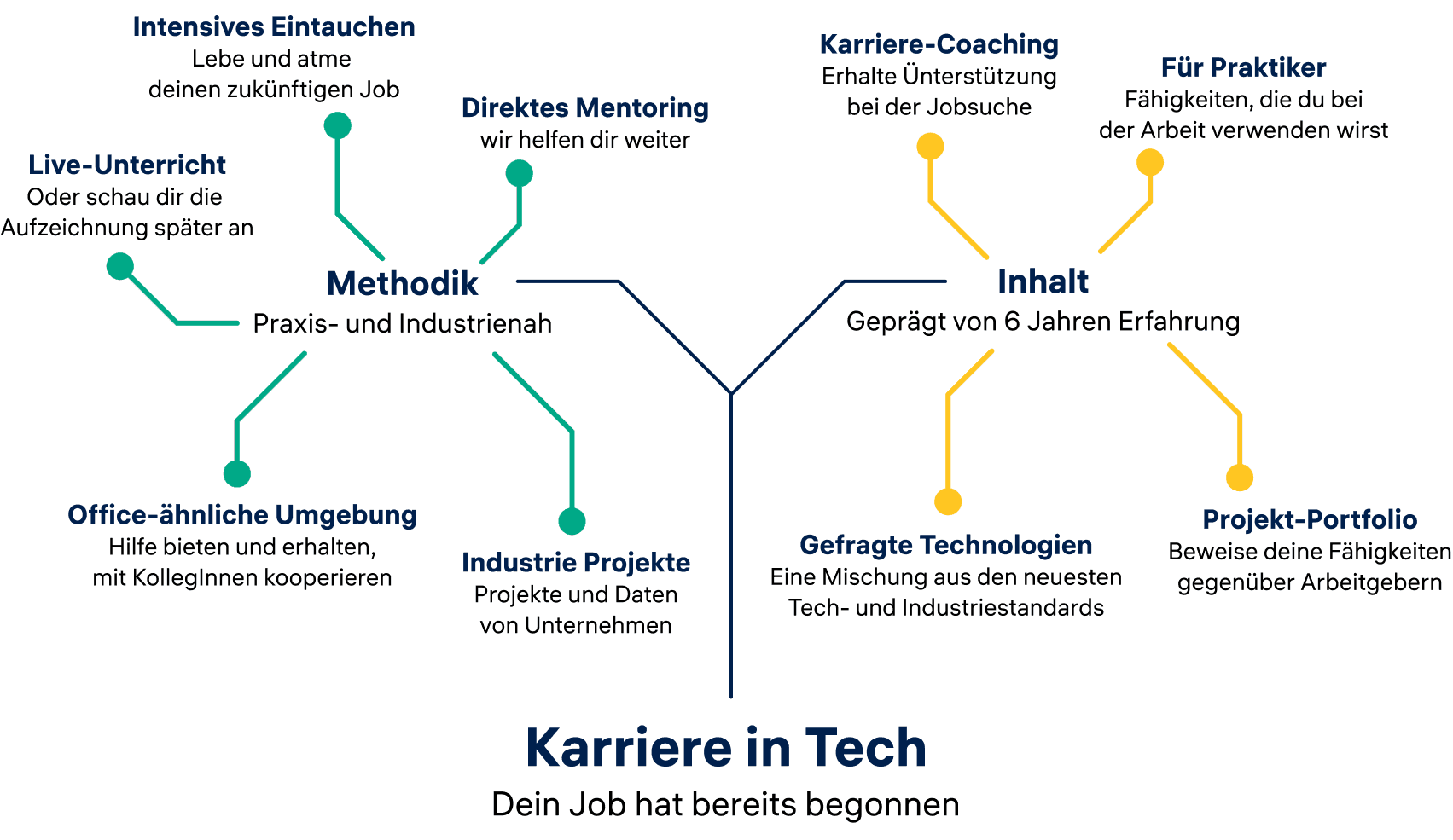
Bei Constructor Academy setzen wir innovative Lehrmethoden ein, um eine umfassende Lernerfahrung zu bieten. Unsere in der Branche erfahrenen Dozenten bieten eine unterstützende Umgebung mit einer Mischung aus Vorlesungen, Projekten und Mentoring. Erwerbe die Fähigkeiten, um im technischen Bereich erfolgreich zu sein und Deine Karriere zu fördern.

Bereit, deine Karriere zu ändern? Schliesse dich uns an!
Wer wir sind
Work hard, play hard. Beim Erlernen neuer Kompetenzen geht es nicht nur um das Wissen, das du erwirbst, sondern auch um deine persönliche Entwicklung. Wir bieten dir ein angenehmes Umfeld mit regelmässigen Veranstaltungen und Apéros, bei denen du dich von den Herausforderungen des Tages erholen und dich mit deinen Mitstudenten und dem Team austauschen kannst.


Unsere Standorte
Zürich
München
Bremen
Online
Programme
Bootcamps
- Karrierewechsel
- Live-Vorlesungen
- praxisorientiert
- Industrieprojekte
- Karrierecoaching
- Finanzierungsmöglichkeiten
- Vorlesungsaufzeichnungen
- lebenslanger Zugriff
- Kontinuierliches Mentoring
- vor Ort oder online
Data Science Programm
Beherrsche die Grundlagen des maschinellen Lernens, um Erkenntnisse aus grossen Datensätzen zu gewinnen.
Full-Stack Programm
Gewinne die Fähigkeiten, von JavaScript bis Python, um eine Karriere in der Webentwicklung zu starten. Erstelle Webseiten, APIs, interaktive Anwendungen und mehr.
Kurzkurse
- Weiterqualifizierung
- online
- Live-Vorlesungen
- Teilzeit
- praxisorientiert
- Abendkurs
- Finanzierungsmöglichkeiten
Python Programmierung
Erfahre mehr über Python-Datenstrukturen, automatisches Scraping von Daten aus dem Web, die Arbeit mit APIs, die Verwendung von Python mit Datenbanken und die Erstellung automatisierter Berichte.
Generative KI meistern
Lerne wie generative KI-Modelle erstellt werden und wie man sie in Anwendungen und Arbeitsabläufe integrieren kann.
Unser Blog
Lies die neuesten Nachrichten über Constructor Academy und informiere dich über alles rund um Programmierung und Data Science in der Schweiz und Deutschland.




Interview mit Data Science Alumnus, Adriano Persegani
von Claudia Boker

Alumni Karrierereport von Constructor Academy
von Claudia Boker

Data Science Abschlussprojekte Batch #21
von Ekaterina Butyugina